Machine Learning Model Management in 2020 and Beyond
Model management is a relatively new issue when it comes to Machine Learning. Since the technique is widely used in business, the need to manage multiple experiments and optimize dozens of parameters has become bread-and-butter of data scientists around the world. And thus, the tools supporting the Model management have emerged on the market. The rise of open-source and relatively intuitive ML frameworks such as Pytorch and Tensorflow has lowered the entry barrier for ML development.
In the coming years, machine learning will only extend its influence and keep penetrating new market segments. Organizations that don’t necessarily have the expertise to build models themselves will be forced to use models made by others.
Deploying and using ML models in such a large, enterprise scope involves a lot of moving parts. Doing it ad-hoc without any solid framework and pipeline in place can make ML development unwieldy and counter-effective. This is where machine learning model management comes into the picture.
Shortcomings of ad-hoc Machine Learning model development
Doing ML model development without a management framework gets very complicated. To name just a few challenges:
- No record of experiments: In an organization, multiple colleagues are likely to be working on the same problem, and they might be running their own set of experiments. In such a scenario, making sure that duplicate work is not being done is essential but hard to implement. For example, colleague A might want to try something out which has already been tried out by colleague B; but he has no way of knowing that, so he has to run the experiment himself. This should be avoided.
- Insights lost along the way: In a rapid iterative experimentation phase, an insight generated in an earlier experiment might be lost when the researcher moves on to the next iterations of that model. A solution would be to keep detailed notes manually, but no one does that just because it’s manual and requires a ton of effort.
- Difficult to reproduce results: Reproducing a particular experiment becomes problematic as that would require storing the model code along with the hyperparameters and the dataset manually, for each and every iteration of the model. This requires a ton of effort, so in practice, no one does it.
- Cannot search for or query models: Once a lot of experiments have been done, querying the past models would be a vital source of information and insights, but without solid version control and metadata tracking system, this becomes nearly impossible.
- Difficult to collaborate: Once a candidate model has been developed and is up for review, how would the reviewer effectively review the model? This problem becomes progressively more challenging as the team size grows. Issue trackers, JIRA boards, pull requests are useful tools designed to solve this problem in the realm of software development, but we need something analogous to that for ML model development too.
Managing the lifecycle of a Machine Learning model with MLops
Machine learning model management can be thought of as a part of a broader framework called MLOps. So before we go into the details of model management, let’s look into details of MLOps.
MLOps can be thought of as a collection of principles, practices, and technologies that help to increase the efficiency of machine learning workflows.
It was inspired by DevOps, as DevOps tries to make the software lifecycle from development to deployment as efficient as possible, the MLOps makes the machine learning development pipeline—from experimentation to deployment—faster and smoother.
The MLOps pipeline can be broadly divided into the following three parts, each optimizing a particular aspect of ML model development.
- Model development and management: This deals with methodologies for faster experimentation and development of models.
- Model deployment: This includes a few subtasks.
- Validation and quality assurance of models that are about to be deployed. After validation, automated, and fast deployment of models into production.
- Deployment of new versions of models, i.e., upgrading, over-the-air seamlessly. This step can be thought of as analogous to continuous integration and continuous deployment of DevOps.
- Model monitoring: Monitoring the usage and performance of models that are running in production. Systems that alert when concept drift occurs are common.
Although these principles are similar to their software engineering or data management counterparts, ML models are fundamentally different from code or data, so they should be treated differently. Software management or data management tooling don’t work as effectively on models. So we have to rethink MLOps on its own.
In this article, we’re going to focus mostly on the first part of the MLOps pipeline: model management.
What is Machine Learning model management?
Now that we have a birds-eye view of what ML model management is, we can look into the specific practices that go into it.
While developing models, researchers carry out lots of experiments rapidly. By experiments I mean trying out different model architectures, tuning their hyperparameters, and then seeing their performance by training and validating. Even if a single researcher is doing these experiments independently, keeping track of all the experiments and their results can become hard.
This challenge grows when multiple researchers are working on the same problem simultaneously. As these experiments tend to be very rapid and somewhat chaotic, traditional software management tools such as git and Kanban boards fall short when it comes to synchronization between researchers and the experimentation phase.
Solving this challenge is the core premise of ML model management. And the solution turns out to be something quite simple but tremendously powerful: logging everything.
By logging the parameters pertaining to every experiment, dashboards can be generated at a central place where everyone can keep track of the different models. In addition, there should also be a way to keep track of all the versions of the models that are developed, so that they can be reproduced later easily.
This is the central idea behind ML model management, and in practice, these techniques end up multiplying the productivity of model developers.
So, we understand, ML model management consists of the following three ideas
- Logging
- Version Control
- Dashboard
Now let’s look at them one-by-one more closely.
Logging
In an ML model development workflow, the fundamental unit of operation is an experiment. An experiment can be thought of as a single train-and-validate cycle of a particular model. Logging every experiment is the first step towards having a birds-eye view of the performance of the models.
For each experiment, the following parameters might be logged:
- The model name, along with a version number.
- Set of hyperparameters used.
- Training accuracy at each iteration of the training process.
- Final test accuracy, or better, the confusion matrix.
- Training time, memory consumed, etc.
- Model binary
- Code and environment configs
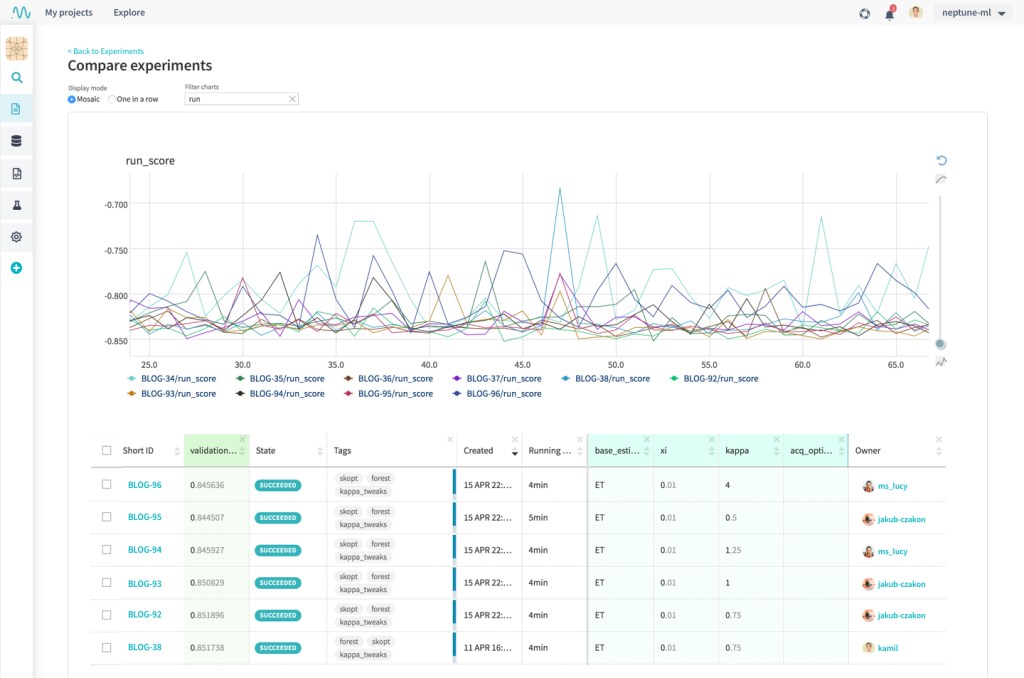 *
*
Version Control
Just like software, machine learning models get built incrementally. After each incremental change, the model might perform differently than before.
So it is of utmost importance to track the version of models that are being used, and make sure that the metadata and performance metrics that are logged are tagged with the name and version of the model that’s being used. This is where version control comes in.
Version control also helps us reproduce a model later easily, as all the information pertaining to the model is stored in the VCS.
As git is the industry-standard version control system for software development, many ML model management frameworks provide a VCS that’s git-like, in terms of architecture and user interface.
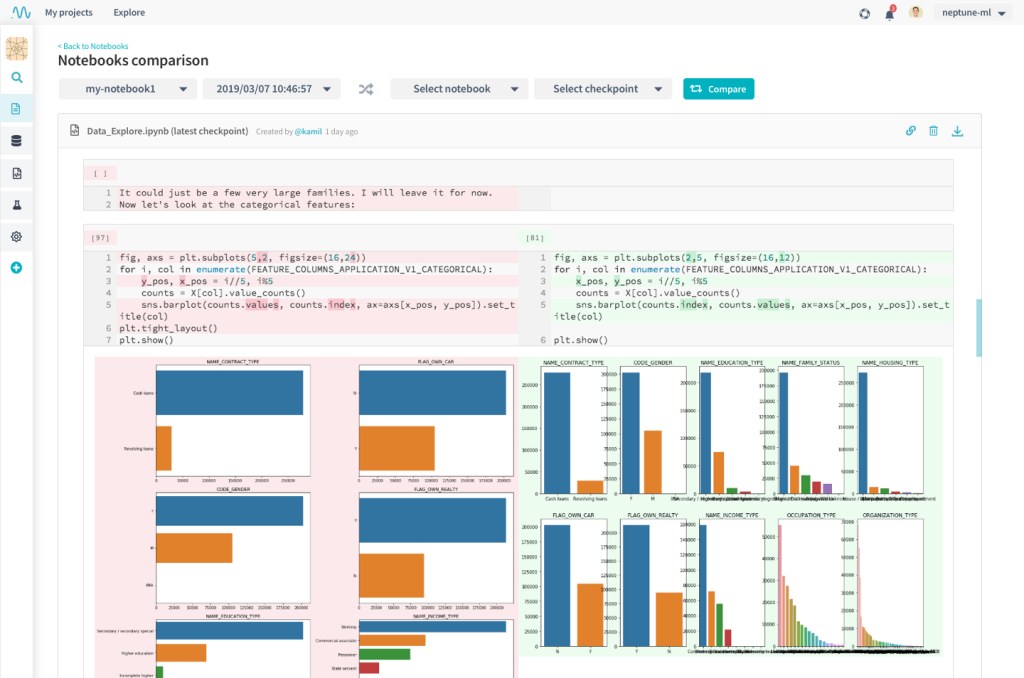
Dashboard
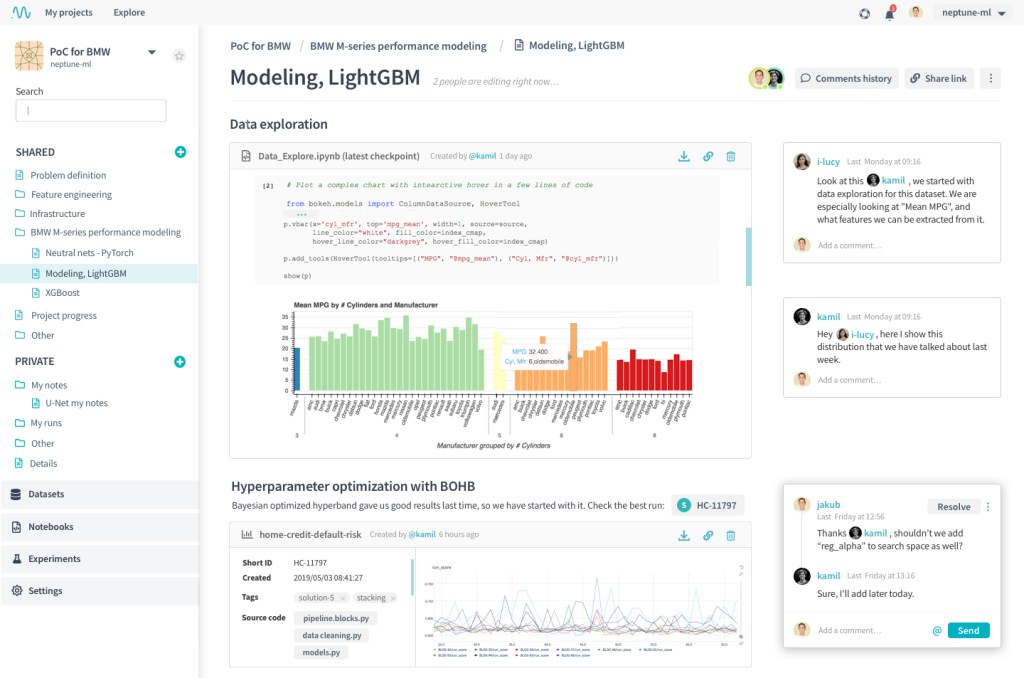
Once all the information and metadata pertaining to the experiments has been collected, a central dashboard is used to
- Visualize the metrics related to the models
- Query all the models and experiments
- Share results with collaborators and review the models
Having an intuitive and powerful dashboard can unlock tremendous potential for collaboration and insight gathering; in a sense generating a powerful and rich dashboard is the final goal of model development.
It also helps if the dashboard has user management, authentication, and authorization features built into it, especially for large organizations. That way, security gets reinforced, and collaboration becomes much more manageable.
Machine Learning model management frameworks
Now that we understand what machine learning model management is, let’s look at some popular model management frameworks. Each has its own idiosyncrasies, strengths, and weaknesses, but they do follow a pattern as well.
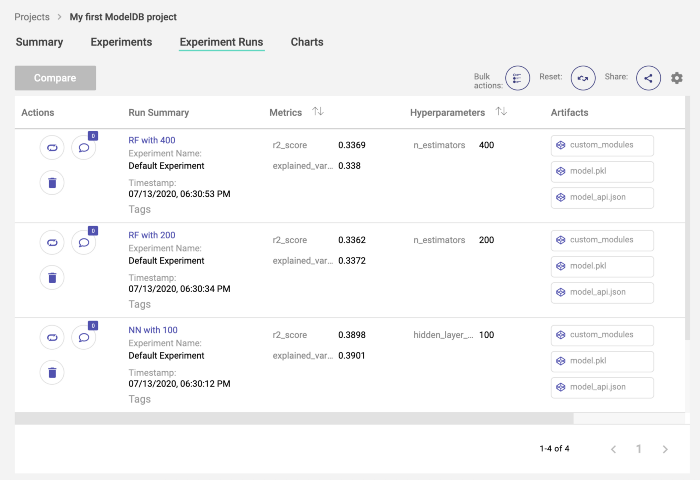
ModelDB
The ModelDB framework is one of the pioneers of making machine learning model management easy and intuitive. The Github repo of ModelDB describes itself as
ModelDB is an open-source system to version machine learning models including their ingredients code, data, config, and environment and to track ML metadata across the model lifecycle.
In essence, it’s a complete system that provides all the primary components of ML model management: logging, version control, and a central dashboard. It consists of a powerful backend built to run as docker containers, a pluggable storage system, and powerful integrations with major ML frameworks such as Tensorflow, Pytorch, and scikit-learn. You can use ModelDB in order to
- Make your ML models reproducible.
- Manage your ML experiments, build performance dashboards, and share reports.
- Track models across their lifecycle including development, deployment, and live monitoring.
ModelDB started off as a research project by the CSAIL research lab at MIT. Since then, it has been adopted by VertaAI and currently it lives here. The latest version of Modeldb brought many features that made it enterprise-ready, including git-based model versioning and authentication features for its central dashboard; the announcement can be found here.
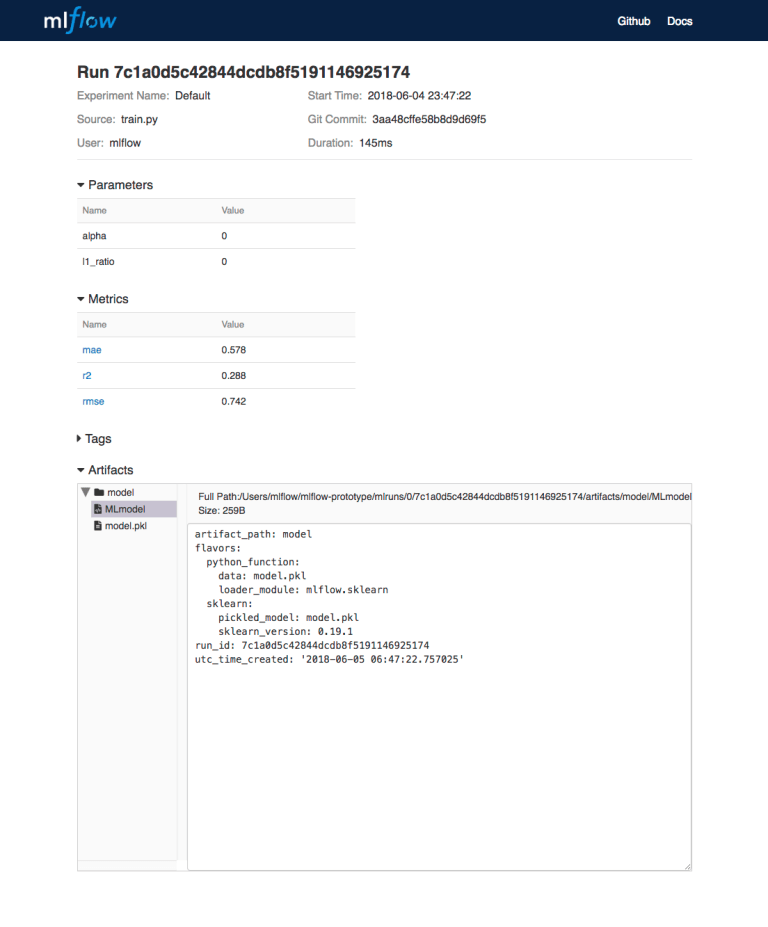
MLflow
MLflow is another big, comprehensive ML model management framework. It’s created by Databricks, the company behind Apache Spark. And it’s really apparent how their talent and experience have been integrated into this giant but agile framework. From its Github repo
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models.
As you can see, MLflow also provides features for deploying ML models, making this more of a full-fledged MLOps framework. MLflow consists of the following components.
-
MLflow Tracking: An API to log parameters, code, and results in machine learning experiments and compare them using an interactive UI. Essentially, this component covers the most fundamental logging part of the ML model management workflow.
-
MLflow Projects: A code packaging format for reproducible runs using Conda and Docker, so you can share your ML code with others. This incorporates the version control part of the model management workflow.
-
MLflow Models: A model packaging format and tools that let you easily deploy the same model (from any ML library) to batch and real-time scoring on platforms such as Docker, Apache Spark, Azure ML, and AWS SageMaker.
-
MLflow Model Registry: A centralized model store, set of APIs, and UI, to collaboratively manage the full lifecycle of MLflow Models. This component, along with the previous one, makes MLOps a fully-fledged MLOps framework, rather than just a model management framework.
Neptune
Neptune is a machine learning experiment management tool which focuses on being lightweight and easy to integrate. It consists of two components,
- The server, which you can use as a service or install on your own hardware.
- The client libraries.
Like I said, the strength of Neptune is in its ease of integration with all kinds of workflows. Using Neptune, team members can use vastly different ML libraries and platforms, and yet share their results and collaborate on a single dashboard.
Moreover, you can use their software-as-a-service offering, skipping the need to deploy it on your own hardware; and that way integrating Neptune into your workflow becomes even easier.
Neptune offers the following features
- Experiment management: Keep track of all the experiments your team carries out; tag, filter, group, sort and compare your experiments.
- Notebook versioning and diffing: Compare two notebooks or two different checkpoints of the same notebook. You can even compare their output side-by-side just like source code.
- Team collaboration: Adding comments, mentioning teammates, comparing results and discovering insights through discussions, it’s all possible.
As you can see, it’s a fully fledged machine learning model management framework; the ease of use doesn’t come at the cost of functionality and power. If you’re looking for an easy entry into the world of machine learning model management, Neptune could be perfect.
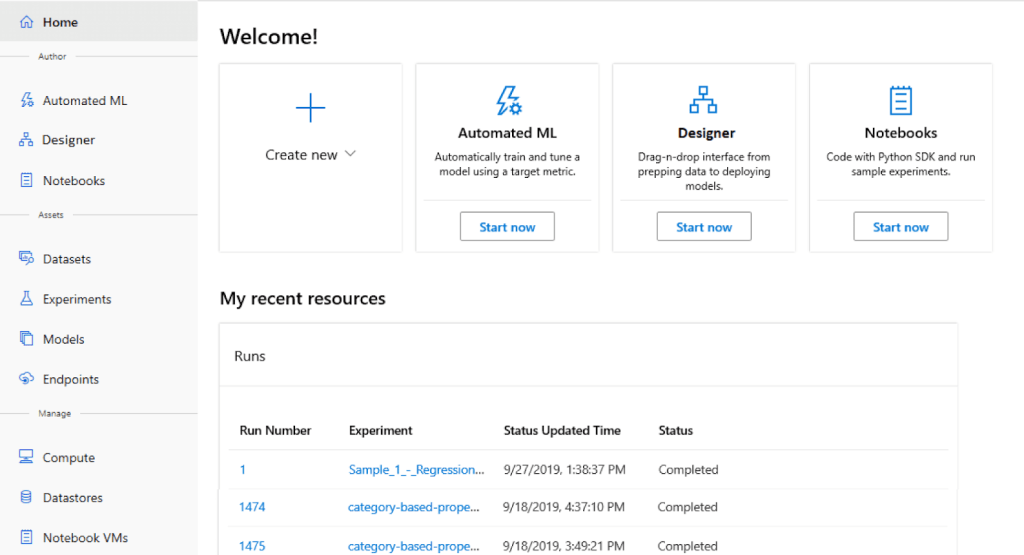
Azure Machine Learning
Azure Machine Learning is the cloud MLOps platform offered by Microsoft. As it’s a complete MLOps system, it offers services to manage and automate the whole ML lifecycle, i.e., model management, deployment, and monitoring. It provides the following MLOps capabilities.
- Create reproducible ML pipelines.
- Create reusable software environments for training and deploying models.
- Register, package, and deploy models from anywhere.
- Deals with data governance for the end-to-end ML lifecycle.
- Notify and alert on events in the ML lifecycle.
- Monitor ML applications for operational and ML-related issues.
- Automate the end-to-end ML lifecycle with Azure Machine Learning and Azure Pipelines.
If you’re considering making your whole ML infrastructure cloud-based, or if you’re already on the cloud bandwagon, Azure Machine Learning might be an excellent platform to consider. It offers all the state-of-the-art MLOps workflows, and you won’t have to manage a single piece of hardware by yourself.
Final remarks
Machine learning model management frameworks make your ML workflow much smoother, lets your team collaborate and share their insights, in turn increasing their efficiency and productivity by a great margin. You should incorporate an ML model management framework in your arsenal; it’s an essential component of using ML effectively in 2020 and beyond.
If you’re new to model management, I would suggest you start with a framework that’s lightweight enough to not add any friction to the workflow and codebase you already have in place. Once you understand how it suits you, and how you can use it to be more productive, you can incorporate it more deeply into your workflow. Neptune is such a framework, it’s lightweight enough to not get in your way, but it’s also powerful if you use it to its full potential.